







Four Reasons It's Essential Stop Stressing About Deepseek
페이지 정보
작성자 Kristen 작성일25-02-18 17:25 조회9회관련링크
본문
You possibly can rapidly discover DeepSeek Chat by looking out or filtering by mannequin providers. They will run on enterprise degree and they have access to both hosted models and self-hosted fashions. 3. 3To be utterly exact, it was a pretrained mannequin with the tiny amount of RL coaching typical of models before the reasoning paradigm shift. As fixed artifacts, they've grow to be the thing of intense study, with many researchers "probing" the extent to which they acquire and readily show linguistic abstractions, factual and commonsense information, and reasoning skills. Those firms have additionally captured headlines with the huge sums they’ve invested to build ever more powerful models. However, the distillation based mostly implementations are promising in that organisations are in a position to create efficient, smaller and correct models using outputs from massive fashions like Gemini and OpenAI. While my very own experiments with the R1 mannequin confirmed a chatbot that principally acts like different chatbots - whereas walking you thru its reasoning, which is fascinating - the true worth is that it factors towards a future of AI that is, at least partially, open supply.
It proves we can make the fashions extra efficient whereas keeping it open supply. FP8-LM: Training FP8 massive language models. Models of language skilled on very massive corpora have been demonstrated useful for natural language processing. We also evaluated well-liked code models at totally different quantization ranges to find out that are best at Solidity (as of August 2024), and compared them to ChatGPT and Claude. Yes, it’s more cost environment friendly, however it’s also designed to excel in several areas compared to ChatGPT. It’s the identical thing when you strive examples for eg pytorch. That discovering explains how Deepseek free could have less computing power but attain the identical or better outcome just by shutting off increasingly components of the network. DeepSeek Ai Chat did this in a manner that allowed it to use less computing power. Australia has banned its use on government units and methods, citing nationwide security considerations. This progressive approach not only broadens the range of training materials but additionally tackles privateness issues by minimizing the reliance on real-world knowledge, which may usually include sensitive data. By delivering more correct results sooner than traditional strategies, groups can give attention to evaluation reasonably than looking for information.
Furthermore, its collaborative features enable teams to share insights easily, fostering a culture of data sharing inside organizations. Furthermore, we improve models’ performance on the distinction units by making use of LIT to reinforce the training knowledge, without affecting efficiency on the unique knowledge. Experimenting with our technique on SNLI and MNLI reveals that present pretrained language fashions, though being claimed to include sufficient linguistic data, struggle on our automatically generated contrast sets. The unique research goal with the current crop of LLMs / generative AI primarily based on Transformers and GAN architectures was to see how we are able to resolve the problem of context and attention lacking in the earlier deep studying and neural network architectures. GPT-three didn’t assist long context home windows, but if for the second we assume it did, then each extra token generated at a 100K context size would require 470 GB of reminiscence reads, or round 140 ms of H100 time given the H100’s HBM bandwidth of 3.Three TB/s. The implementation was designed to assist multiple numeric varieties like i32 and u64.
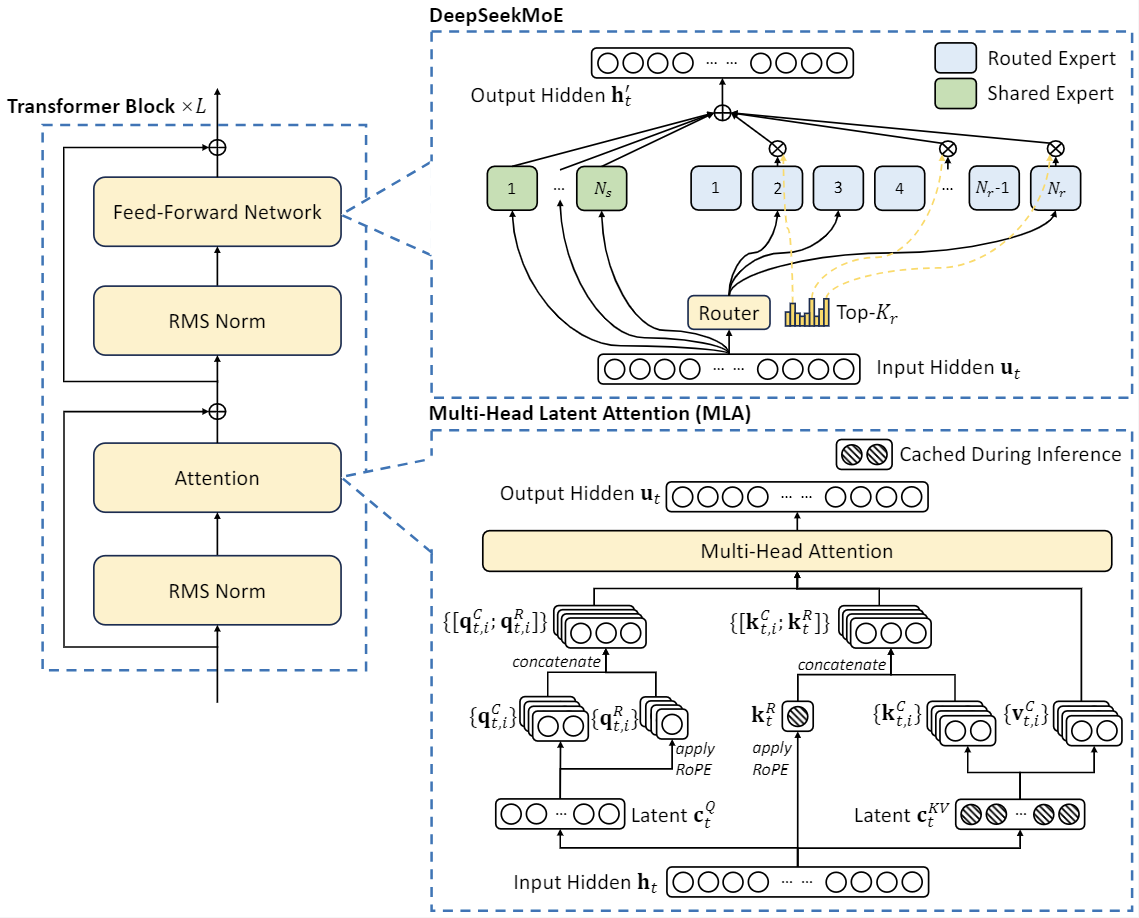 However, whereas these fashions are helpful, particularly for prototyping, we’d nonetheless prefer to caution Solidity builders from being too reliant on AI assistants. Unfortunately, these tools are often bad at Solidity. It takes more time and effort to grasp however now after AI, everyone seems to be a developer as a result of these AI-driven instruments simply take command and full our needs. Get started with the Instructor utilizing the next command. Put another method, whatever your computing power, you'll be able to increasingly turn off components of the neural net and get the identical or better results. Graphs show that for a given neural web, on a given quantity of computing price range, there's an optimum amount of the neural internet that can be turned off to achieve a level of accuracy. Abnar and workforce ask whether or not there's an "optimum" level for sparsity in DeepSeek and similar fashions, which means, for a given quantity of computing power, is there an optimum number of these neural weights to turn on or off? In the paper, titled "Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models," posted on the arXiv pre-print server, lead creator Samir Abnar of Apple and different Apple researchers, together with collaborator Harshay Shah of MIT, studied how efficiency different as they exploited sparsity by turning off components of the neural net.
However, whereas these fashions are helpful, particularly for prototyping, we’d nonetheless prefer to caution Solidity builders from being too reliant on AI assistants. Unfortunately, these tools are often bad at Solidity. It takes more time and effort to grasp however now after AI, everyone seems to be a developer as a result of these AI-driven instruments simply take command and full our needs. Get started with the Instructor utilizing the next command. Put another method, whatever your computing power, you'll be able to increasingly turn off components of the neural net and get the identical or better results. Graphs show that for a given neural web, on a given quantity of computing price range, there's an optimum amount of the neural internet that can be turned off to achieve a level of accuracy. Abnar and workforce ask whether or not there's an "optimum" level for sparsity in DeepSeek and similar fashions, which means, for a given quantity of computing power, is there an optimum number of these neural weights to turn on or off? In the paper, titled "Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models," posted on the arXiv pre-print server, lead creator Samir Abnar of Apple and different Apple researchers, together with collaborator Harshay Shah of MIT, studied how efficiency different as they exploited sparsity by turning off components of the neural net.
댓글목록
등록된 댓글이 없습니다.


